
As a C programmer you are probably familiar with the idea of functional
decomposition.
The idea behind this is that when you design and implement a program,
you most likely
subdivided the programming effort by breaking the work of the program
into a set of
key functions, which may themselves in turn call on other functions.
This divide and conquer
approach to programming is very powerful as it allows the programmer
to concentrate on
small, easily devised and debugged subroutines. Even today, with
the rise of object oriented
programming, this approach is still very useful in small to medium
sized programming endeavors
as it closely follows the way people deal with large complex tasks.
The design and implementation of programs using a functional approach
alone begins to become
problematic as the size and complexity of the program increases.
Consider the following scenario:
A company is 80% through a software development project when the client
(or some other factor)
introduces a change which requires a significant change in a key data
structure used throughout
the program. As a result, every function which makes use of strucures
of this type must be checked
for compatibility and fixed if necessary. The problem?
The functions are designed with a particular
data model in mind. If the model changes so too must the functions.
The same problem will also arise
if the company decides to release Version 1.2 of the program which
includes extra features. This is
where Object Oriented programming (OOP) steps in.
There are three basic principles associated with OOP:
OOP is possible in many different languages : and not necessarily just the Object Oriented ones asSame functionality: two implementations, one interface.
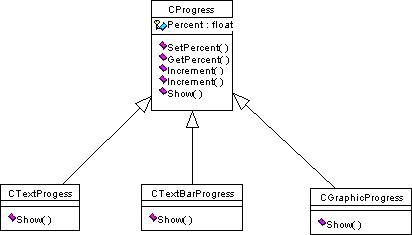
The lower three classes are specialised versions of a generalised Progress
class called CProgress (the notation
here is Unified Modelling Language:- UML). These specialised
classes differ in the way they display their output therefore they
each have their own version of Show which writes data to the screen.
When the program is executed, the function
"SomeLongProcess" is called and passed the address of three objects
(derived from CProgress) with which it interacts. The
"long process" calls upon the various methods in the CProgress object
including the Show method.
Lets take a close look at this "SomeLongProcess" routine:
void SomeLongProcess(CProgress *prog)
{
for (int i=0; i < 11 ; i++)
{
cls();
prog->SetPercent(i*10);
prog->Show(); // as if by magic, the correct version of
show is called each time
// polymorphism in action.
printf("\nPress a key\n");
_getch();
}
}
The declaration implies that the routine will accept only the address
of a CProgress object. Under C++ however,
it is also legal to pass the address of any object which is an instance
of a class derived from CProgress. This makes
perfect sense; afterall, a CTextProgress object is a sort of CProgress
object. (It is not legal however to use the
class hierarchy in the opposite way. Suppose you write a routine
which is passed the address of a CTextProgress
object. In this instance it would not be legal to pass the address
of a CProgress object or indeed a CTextBarProgress
object nor a CGraphicProgess object: only objects which are specialised
versions of CTextProgress are permitted).
During the course of SomeLongProgress, a call is issued to Show.
When you run the program, you will notice that
the correct version of Show is called in each case even though there
seems to be no code to support this. What's
going on? Polymorphism. The same line of code
prog->Show();
produces three different results.
How is it that the computer knows which version of Show to call?
There must be some information in the "prog"
object which the computer can read and therefore figure out the correct
version of Show to call. Well, there is. You
will notice that the Show function is declared as "virtual" in CProgress
and its derived classes. This keyword causes the
compiler to generate code in such a way that the address of the correct
version of Show is included in each instance of
CProgress (and derived) classes. The compiler also generates
code which looks up this address at each call to Show.
This is the mechansim by which polymorphism is achieved. If there
are several virtual functions in a class, the compiler
generates a lookup table of these function addresses and attaches it
to each instance of that class. This table of function
address is known as a V-table.
class
Used when declaring a class 'type', similar to the keyword 'struct'.
e.g.
class MyClass {
.
.
.
}; // DON'T FORGET THE TRAILING SEMICOLON!
This declares a new class type. Classes, unlike structs can contain
functions (methods)
as well as variables (attributes).
public:
When used inside a class, in advance of the declaration of some variable
or method,
this keyword specifies that the variable or method is to be accessible
to other functions
within your program (outside of the class).
e.g.
class MyClass {
public:
int i;
int GetValue();
.
.
}
The above would enable other functions within your program (e.g. main)
to directly
access and modify i and to call GetValue.
When public preceeds the name of a base class, this implies that the public
and protected
members of the base class will become public and protected members of the
derived class.
e.g.
class MyOtherClass : public MyClass {
}
i and GetValue will appear, to the rest of the program, to be public members
of MyOtherClass.
private:
The private keyword locks away variable and methods inside a class in such
a way that only
functions which are members of that class can access them. It is
used in a similar manner to
'public'. You may wonder why you would want to hide variables and
methods in such a manner.
The answer lies in Encapsulation. By using 'private' you can ensure
that other parts of your
program do not rely on a particular implementation approach inside a class.
You can also
use private to stop other parts of your program from meddling with the
contents of some critical
variable within your class (such as a pointer or a file handle).
protected:
The protected keyword is very similar to private in that it is used to
obscure implementation and
protect sensitive program areas. 'protected' is a less draconian
form of private in that it will allow
classes derived from the one you are working on to access protected variables
and methods.
virtual:
As stated above in the Progress1 example, the virtual keyword is used to
force the compiler to
insert code which implements late binding. Late binding is
the process where a functions address
is determined at run-time rather than at link time. You typically
declare virtual functions in the following
manner
class MyClass {
public:
virtual void SetValue(int NewValue);
}